

こんにちは。SB C&S の村上です。
この記事ではGPUDirect Storageを使い、ストレージ・GPU間の高速なデータ転送を行います。
GPUDirect Storageの概要については以下の記事をお読みください。
GPUDirect Storageの紹介
実施する内容
本記事では「GDSあり」と「GDS無し」のそれぞれで、GPUとローカルNVMeストレージ間にて100GBのデータセットのデータ転送を行います。
実行はNGCのコンテナを起動し、その中でPythonにてkvikioのライブラリを使います。
環境準備
本記事で用いる環境は以下となります。
- プラットフォーム: DGX H200
- GPUドライバインストール済み
- CUDAインストール済み
- コンテナランタイム & NVIDIA Container Toolkitインストール済み
- nvidia-fs (GDS カーネルドライバ) インストール済み
※本環境ではGDSのカーネルドライバは標準でインストール済みとなります。インストール方法は環境によって異なるため、以下ドキュメントをご参照ください。
https://docs.nvidia.com/gpudirect-storage/troubleshooting-guide/index.html#installing-gds
また、今回データ転送に用いる100GBの画像データセットを以下ファイルとして準備済みです。
/raid/gds_demo/dataset_100g.bin
コンテナの起動
それでは実行用のコンテナを起動していきます。
コンテナイメージはNGC上のPytorchコンテナを使います。
https://catalog.ngc.nvidia.com/orgs/nvidia/containers/pytorch?version=25.05-py3
なお、コンテナ内でGDSを使う場合に、注意するべき点があります。
GDSは用いるストレージデバイスの情報を取得して対応しているかを認識します。今回用いるNVMeの場合はホスト側のudevから情報を取得するため、コンテナに/run/udevディレクトリを読み取り権限でマウントする必要があります。
マウントオプション: -v /run/udev:/run/udev:ro
それでは以下コマンドでコンテナを起動します。
オプションとしてはGPUコンテナとして必要なオプションに加えて、NVMeストレージ(/raid)およびudevディレクトリをマウントしています。
docker run -it -d \
-p 9000:8888 \
--gpus '"device='0'"' \
--shm-size=16g \
-v /raid:/raid \
-v /run/udev:/run/udev:ro \
--name gds-demo \
nvcr.io/nvidia/pytorch:25.05-py3
このあとGDSを実行していくためには、cuFileAPIが必要となります。
なお、今回起動したPytorchのコンテナは標準でcuFileAPIがインストールされています。試しに以下コマンドでインストールされていることを確認しておきます。
docker exec -it gds-demo apt-cache search libcufile
## 出力
libcufile-12-9 - Library for GPU Direct Storage with CUDA 12.9
libcufile-dev-12-9 - Library for GPU Direct Storage native dev links, headers
続いて、以下コマンドでPythonコードを実行するためのJupyterLabを起動しておきます。
docker exec -d -it gds-demo \
jupyter lab --allow-root --ip=0.0.0.0 \
--no-browser --NotebookApp.token=''
実行後、ブラウザからコンテナのポート番号(9000)にアクセスをし、JupyterLabの画面が表示されることを確認します。
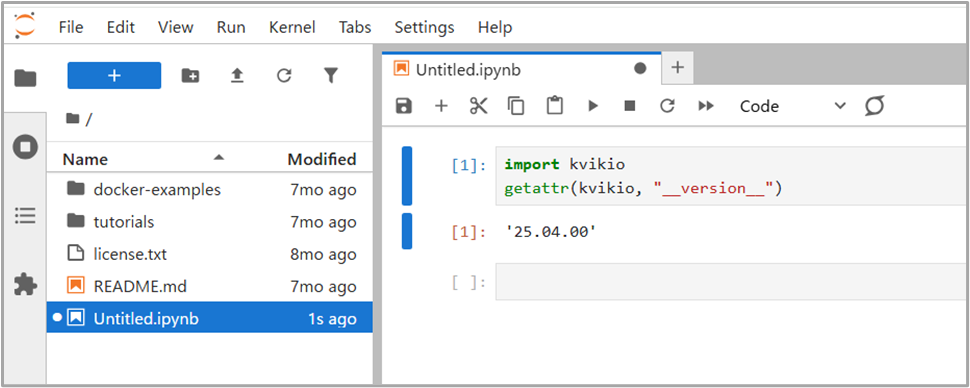
無事に起動が確認できたら、ノートブックを1つ作成し、GDSのライブラリを確認します。
今回利用するコンテナではGDSのライブラリであるkvikioが標準でインストールされているため、以下のように問題なくインポートできます。
GPUへのデータ転送の実行
それではPythonのコードにて「GDSあり」と「GDS無し」それぞれでGPUへのデータ転送を行っていきます。
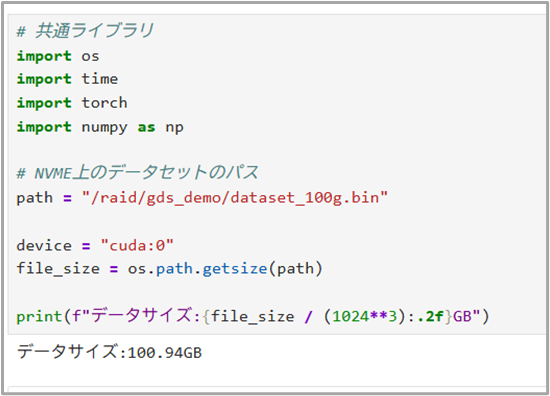
まず共通のライブラリのインポートや、データセットのパス指定などの事前準備として以下を実行します。
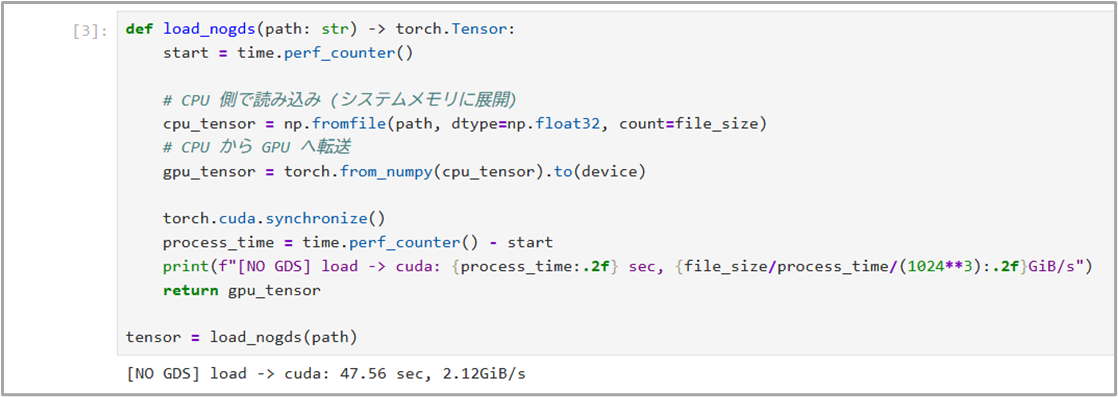
では従来のデータ転送(GDS無し)の処理を実行していきます。
今回は比較用として処理にかかった時間を取得できるようにした以下コードを実行し、出力結果を確認すると47秒かかったことが確認できます。
以下コードを実行して一度GPUメモリをリフレッシュします。
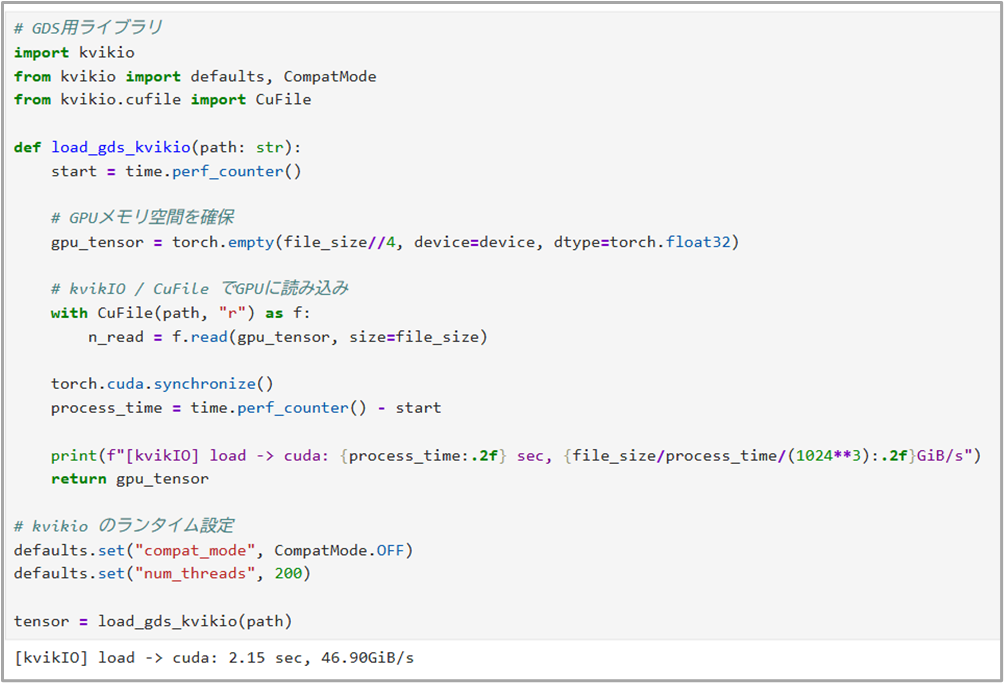
それではGDSでデータの読み込みを行うコードを実行していきます。
※defaults.setのコードはGDSのパラメータ設定を行っているものになります
結果を確認すると、実行時間はわずか2秒でした。
実行の度に多少前後しますが、今回の結果上では「GDS無し」と比較して約20倍の速度で完了しています。
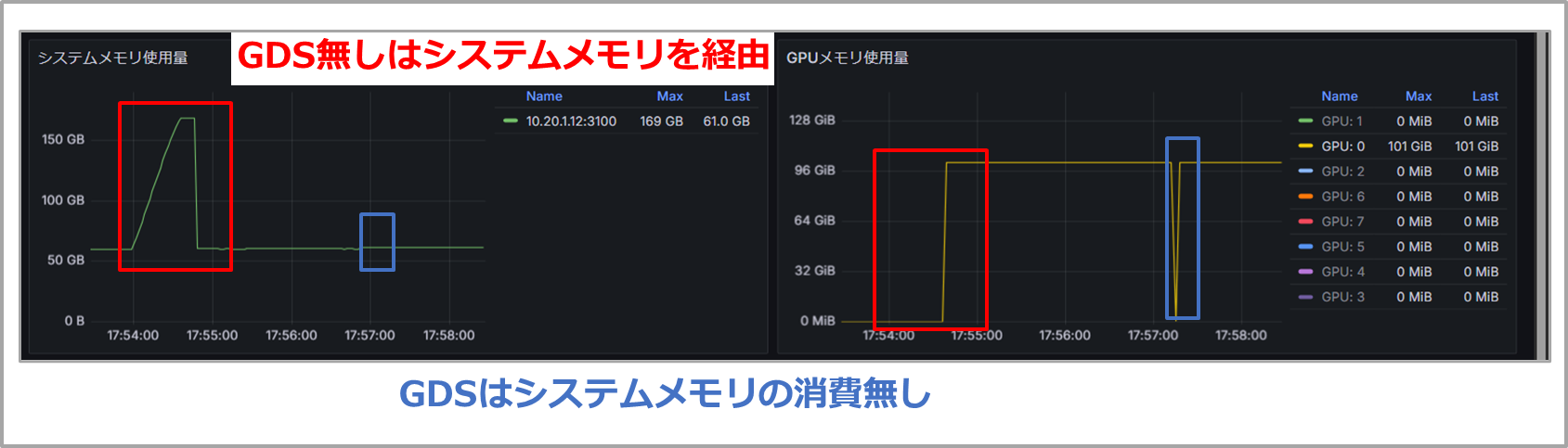
実行中のシステムメモリとGPUメモリのログを確認すると、GDS実行時にはシステムメモリが使われていないことも確認できます。
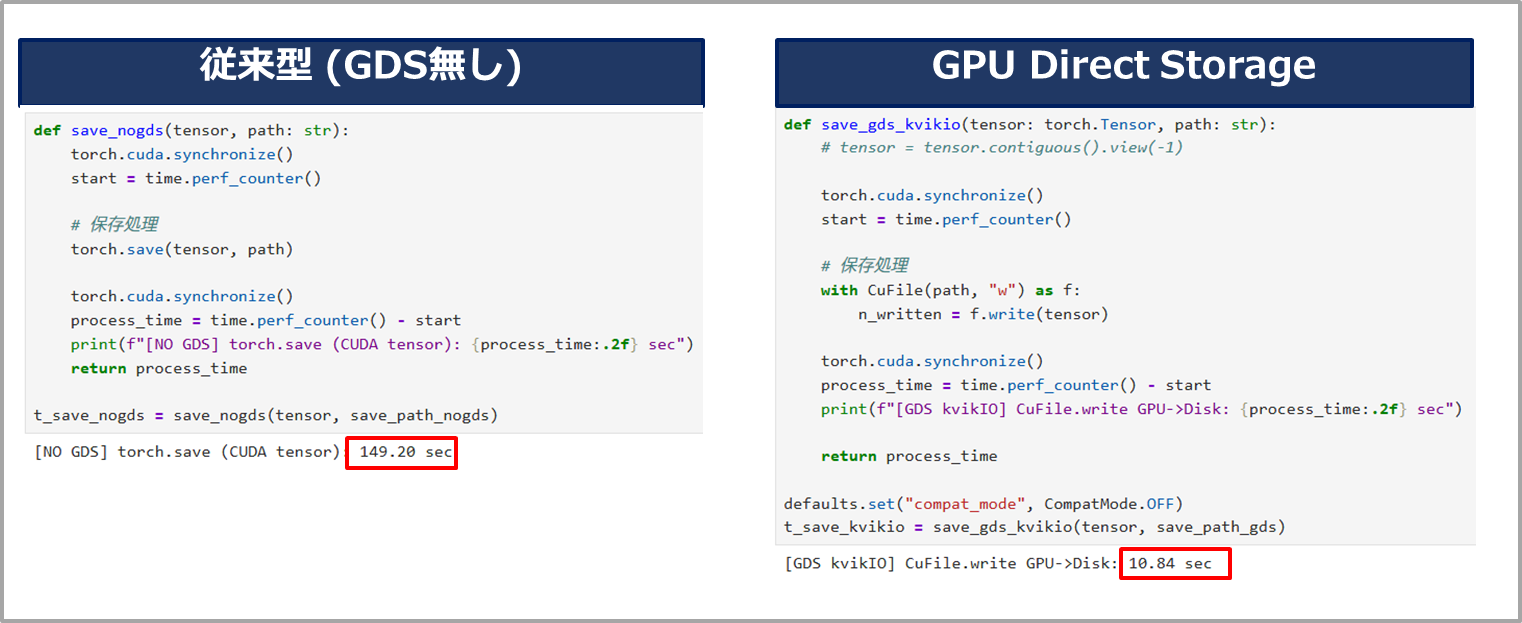
また、過程は省略しますが、GPUからストレージへデータの保存をする場合の結果は以下のようになりました。
こちらも同様にGDS無しと比較して高速に完了していることが確認できます。
このようにGDSによりシステムメモリを経由しないことで、処理を高速化できていることが確認できました。
まとめ
本記事では実際にGPUDirect Storageを使う流れを紹介しました。
ドライバ関連の準備が出来ていれば簡単に使い始められることが確認できたかと思います。また、利用した結果としてもGDSを使うことで目に見えて差が確認できました。
今後のAI開発の際にぜひお試しください。
他のおすすめ記事はこちら
著者紹介

SB C&S株式会社
ICT事業本部 技術本部 第1技術統括部
第2技術部 1課
村上 正弥 - Seiya.Murakami -
VMware vExpert




