こんにちは。SB C&Sの野木です。
この記事は、【速報】NVIDIA GTC 2026 Keynote Session (基調講演) レポート の番外編として作成しております。ぜひ本編もご覧ください。
2026年3月16日より開催されたNVIDIA GTC 2026では、「Agentic AI」が中心テーマとして掲げられ、AIは学習中心から推論中心へとシフトしていることが強調されました。
その実現に向けては、低レイテンシ・大規模コンテキスト・高スループットといった要件が求められます。
これに対応するため、NVIDIAはGPU単体の性能向上ではなく、インフラ全体を再設計するアプローチを打ち出しています。
本記事では、次世代AI基盤「Vera Rubin NVL72 」「NVIDIA Groq3 LPX」「NVIDIA STX」を中心に紹介します。
次世代AI基盤 Vera Rubinの発表
Vera Rubinは、CPU・GPU・ネットワーク・ストレージを統合したAIスーパーコンピューターとして設計されています。
Keynoteでも紹介された通り、「7つのチップ」と「5つのラック」で構成され、単一のPOD(ラック群)が1つのシステムとして動作します。
ここでいうPODとは、複数のラックを束ねた単位であり、単一ノードではなくシステム全体を一体として扱う設計を指します。

NVLプラットフォームでは、Rubin GPUやVera CPUに加え、NVLink™ 6(GPU間高速接続)、ConnectX®-9 SuperNIC™(高性能NIC)、BlueField®-4 DPU(データ処理オフロード)、Spectrum-6 Ethernet Switch(AI向けネットワーク)までを一体で共同設計しています。
これにより、NVIDIAがチップ単体ではなく、AIファクトリー全体を一つの製品として提供しようとしている方向性が示されているといえます。
ここからは、Keynoteで紹介された製品についていくつか取り上げていきます。
NVIDIA Vera Rubin NVL72
NVIDIA Vera Rubin NVL72は、72個のRubin GPUと36個のVera CPUに加え、NVLink 6およびネットワーク基盤を含めて設計されたラックスケールのAIスーパーコンピューターです。
GPU間はNVLinkにより接続され、ラック全体が一つの巨大なGPUのように動作する構成となっています。
計算性能はNVFP4推論で3,600 PFLOPS、NVLinkの帯域幅は260TB/sと、エージェント型AIに求められる大規模処理を支える性能が示されています。
Keynoteでは、Blackwell世代とRubin世代の推論性能の違いが以下のグラフで示されました。
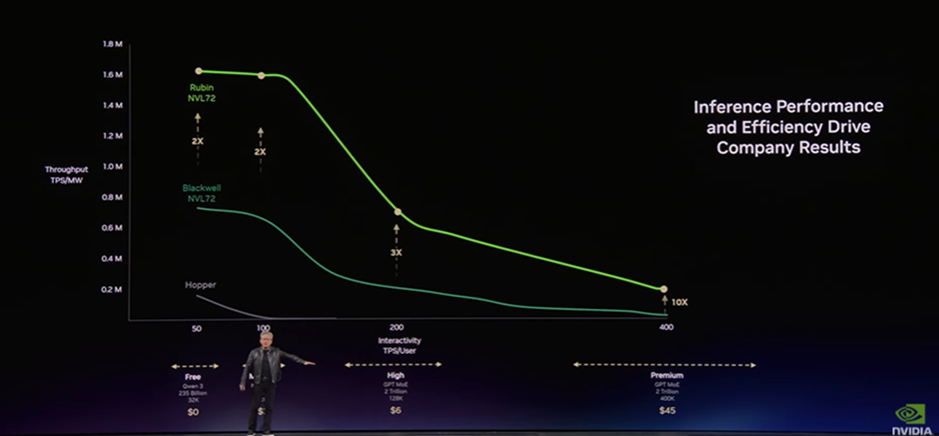
縦軸はスループット(TPS/MW:メガWあたりのトークン数)、横軸はユーザーインタラクティビティ(ユーザー1人あたりのトークン数)を表しています。
AIサービスは用途に応じて、効率重視(無料・バッチ処理)と応答性重視(Premium)に分かれます。
Rubin NVL72とBlackwell NVL 72を比較すると、Rubin世代では従来のBlackwell世代で見られた「応答速度を高めるとスループットが低下する」というトレードオフが大きく改善されています。
特に、より応答性が重視されるPremium帯においても高いスループットを維持できるため、リアルタイム性と効率を両立したAIサービスの提供が可能になります。
このような特性は、単なる性能向上にとどまらず、ビジネス価値にも直結します。
Keynoteでは、Blackwell世代と比較してRubin世代では、同一電力あたりの年間収益が大きく向上することが示されました。
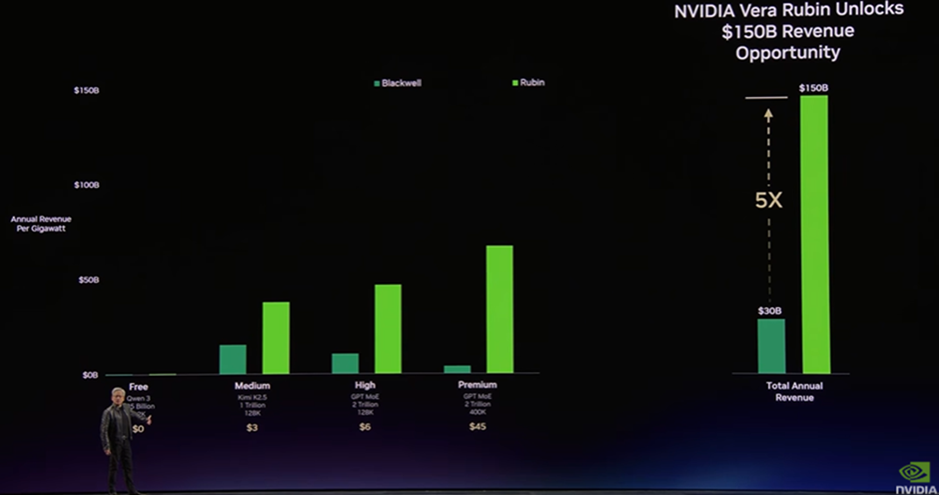
特に、高い応答性が求められるサービス領域において収益性の伸びが顕著であり、全体として最大5倍の収益機会が見込まれるとされています。
また、NVIDIA Rubinプラットフォームでは第6世代のNVLink(NVLink 6)が採用されています。
NVLink 6はGPU間の高速接続を担うインターコネクトであり、スイッチを介してラック内のGPUを単一ドメインとして接続します。
単に帯域を拡張するだけでなく、GPU間通信を前提としたワークロード(例:MoEや長文推論)に対応する設計となっています。
Keynote では、実機を用いたNVLinkの紹介がされており、ラック内のGPUを一体として動作させるアーキテクチャが強調されていました。

さらに注目されたのが、シリコンフォトニクスの位置づけです。
NVIDIAはSpectrum-X™ Photonicsを通じて、光接続を将来的な技術ではなく、実運用を前提としたAIネットワークの拡張手段として位置付けています。
Co-packaged optics(CPO)により、光エンジンをスイッチ近傍に統合することで、従来のプラガブル光モジュールにおける電力・配線・信号品質といった課題の改善が図られています。

NVIDIA Groq 3 LPX
先日、NVIDIAがAI推論技術に関する非独占ライセンス契約を締結したことで話題になったGroqのテクノロジーが、さっそく具体的なプロダクトとして発表されました。
NVIDIA Groq 3 LPXは、エージェント型AIに求められる大規模コンテキストと低遅延処理に対応するため、Vera Rubinと共同設計された推論専用ラックです。
ラックあたり256基のLPU(Language Processing Unit)を搭載し、HBMを搭載したRubin GPUと組み合わせることで、長文コンテキストにおいても低レイテンシかつ高スループットな推論を実現します。
Keynoteでは、以下のようにLP30チップをLPXトレイあたり8枚搭載する構成も紹介されていました。(左側)

さらに、Groq 3 LPXと Rubin NVL72と組み合わせることで、推論性能は向上します。
Keynoteでは、Rubin単体に加えてLPXを組み合わせた場合の性能も示されており、特に高インタラクティビティ領域においてその効果が顕著に現れています。
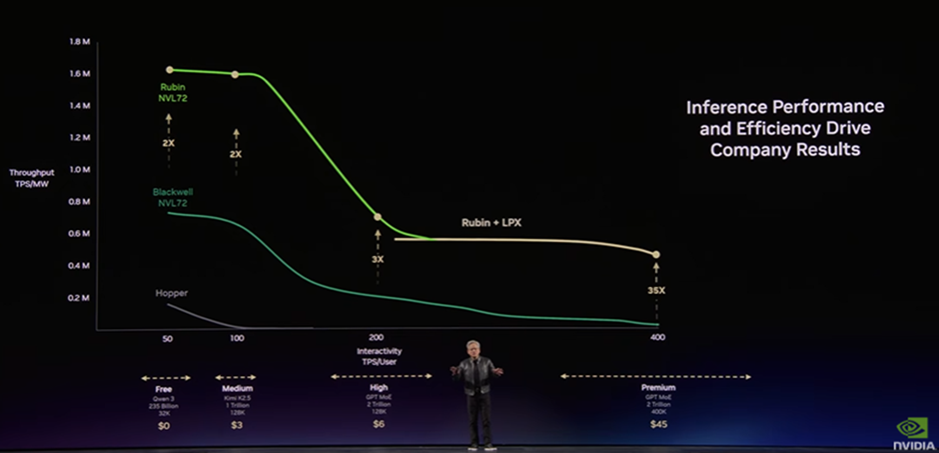
Rubin単体でもBlackwell世代と比較して大幅な性能向上が見られますが、LPXを組み合わせることで、高い応答性を維持したままスループットをさらに引き上げることが可能となります。
特にPremium領域では、Blackwell世代と比較して最大35倍の性能向上が示されており、推論専用基盤を組み合わせることによる効果が強調されています。
Vera Rubin NVL72やNVIDIA Groq 3 LPXは2026年後半の提供が予定されています。
参考:https://developer.nvidia.com/blog/inside-nvidia-groq-3-lpx-the-low-latency-inference-accelerator-for-the-nvidia-vera-rubin-platform
NVIDIA BlueField-4 STX
NVIDIA BlueField-4 STXは、BlueField-4 DPUを中心に、Vera CPUおよびConnectX-9 SuperNICを組み合わせたストレージラックです。
Keynote 2026では以下のようにNVIDIA BlueField-4 STXを紹介しています。(左側)

NVIDIAは、BlueField-4 STX Storage ArchitectureとCMX(Context Memory Storage)を通じて、ストレージを単なるデータ保存領域ではなく、AI推論時の文脈(コンテキスト)を保持・再利用するための層として位置付けています。
CMXではこれを専用の高帯域ストレージ層へオフロードし、POD全体で共有・再利用可能にします。
これにより、推論コンテキストをセッションやエージェント間で再利用できるようになり、従来のストレージとは異なる役割を担う構成となっています。
ストレージ/製造パートナーには、Cloudian、DDN、Dell、Hitachi Vantara、HPE、IBM、MinIO、NetApp、Nutanix、VAST、WEKA、AIC、Supermicro、QCT などが参画しており、STXベース製品も2026年後半の提供が予定されています。
NVL72からKyberへ、AIファクトリーの拡張
ここまでVera Rubin NVL72を中心としたラックスケールの構成を見てきましたが、NVIDIAはさらにその先のスケールを見据えています。
Keynoteでは、BlackwellからRubin、さらに次世代へと続くロードマップが示されており、チップ単体ではなく、ラック、そしてデータセンター全体へとスケール単位が拡張されていることが強調されていました。
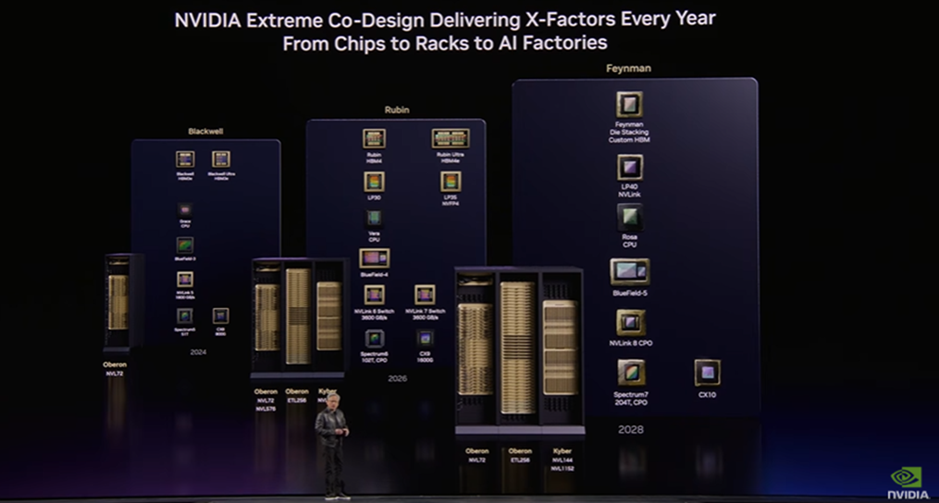
Rubin世代ではNVL72が1つの基本単位として提示されていますが、これをさらに拡張した構成として、Kyber(NVL144やNVL1152)が示されています。
これらは複数ラックを前提とした構成であり、256枚や1152枚のGPU規模の大規模AI基盤を想定したアーキテクチャとなっています。
さらにロードマップでは、2028年に向けた次世代プラットフォーム「Feynman」も示されており、チップ・インターコネクト・ネットワークを含めた統合設計が継続的に進化していく方向性が示されています。
このようにNVIDIAは、AI基盤の単位をサーバーからラック、そしてデータセンターへと拡張し、「AIファクトリー」としてインフラ全体を設計する方向へと進んでいることが分かります。
まとめ
以上、GTC Keynote 2026のうちVera Rubi関連のレポートでした。
今回の発表では、AI基盤がGPU単体から、推論・ストレージ・ネットワークを含めた「AIファクトリー」へと進化していることが示されています。
今後のAIインフラは、このような統合設計を前提に検討していく必要がありそうです。
引き続き、弊社では最新情報をキャッチし随時発信していきますので、ぜひお楽しみにください。
著者紹介
SB C&S株式会社
ICT事業本部 技術本部 第1技術統括部
第2技術部 1課
野木 空良 - Sora Nogi -
サーバー・ネットワークを中心として、AIインフラ全般のプリセールス業務に従事。