


こんにちは。SB C&S の間山です。
この記事では、NVIDIA社が提供する Base Command Manager をご紹介します。
本連載の構成は以下の通りです。
第1回(本稿):NVIDIA Base Command Managerのご紹介
第2回:BCM Head Nodeの環境構築
第3回:GPUクラスタの構成
1.1 NVIDIA Base Command Managerとは何か
Base Command Manager (以下BCM)は、AIデータセンター向けのクラスタ管理ソフトウェアで、クラスタのプロビジョニング、ワークロード管理、インフラ監視を統合して提供します。
「設計/構築(Slurm/Kubernetesなどの導入・設定・運用統合)/運用(監視)」を、まとめて扱うための基盤ソフトウェアです。
1.2 GPUクラスタ運用が難しくなる理由
GPUサーバを1台から複数台へ増やすと、課題は性能そのものよりも運用の再現性に変化します。
Day0(設計)論点
- 論点管理、ストレージ、アウトバンドネットワークの分離と設計
- PXE/DHCP、DNS、NTP、など、クラスタ基盤としての前提整備
- ノード追加時に誰が何をどう実施するか(手順の標準化、権限設計)
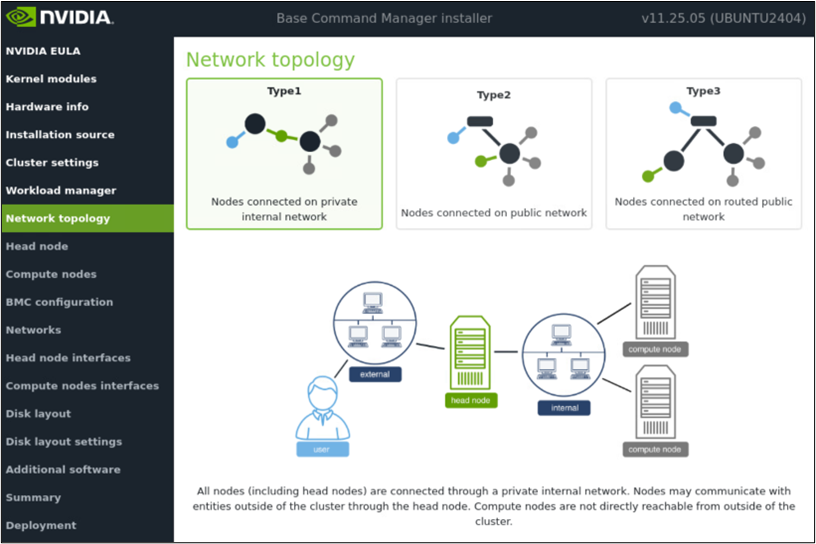
以下は一例です。まずは、クラスタ内に閉じたネットワーク構成(Type1)を示します。
その他の接続タイプはのちの章にて解説していきます。
Type1(Private internal network)
全ノード(Head Node/Compute Node)はクラスタ内のプライベートネットワークに収容されます。外部(ユーザー端末やインターネット等)との通信はHead Nodeを経由して行い、Compute Nodeは外部から直接到達できません(Head Nodeが踏み台/ゲートウェイの役割を担います)。
Day1(構築)論点
- OS展開・ドライバ・OFED・CUDA等の組み合わせ管理
- ノード役割(login、compute、mgmt)やソフトウェアイメージの管理
- SlurmやKubernetesなどの導入と、基盤との接続点(GPU、ネットワーク、監視)の設計
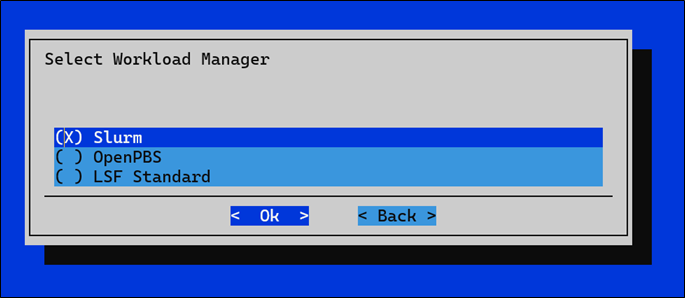
Slurm(ジョブスケジューラ)の登録の例
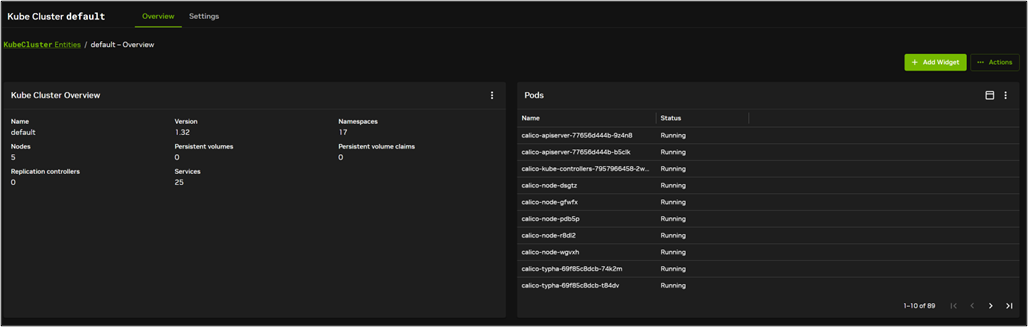
kubernetesリソースの確認例
Day2(運用)論点
- 障害切り分け(GPU不調、リンクダウン、サービス停止、GPU温度...)
- パッケージ更新、セキュリティ対応(CVE)、構成ドリフト抑制
- 利用状況の可視化、キャパシティ管理
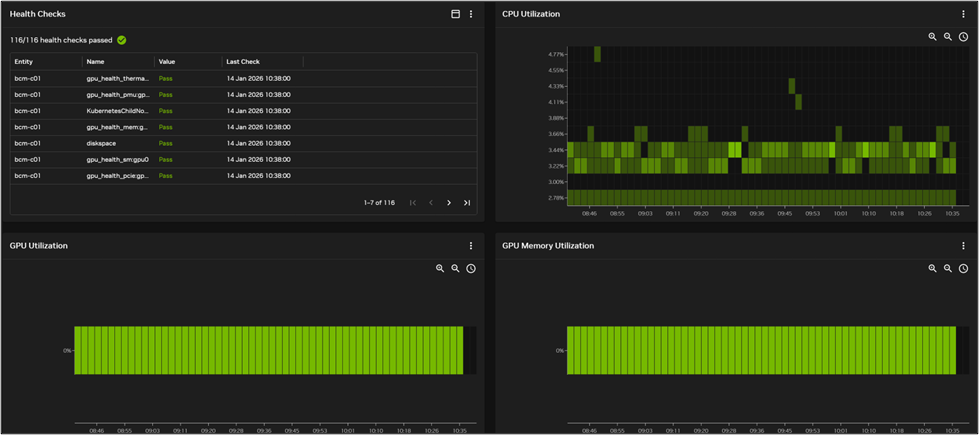
workerノードのGPUステータス確認例
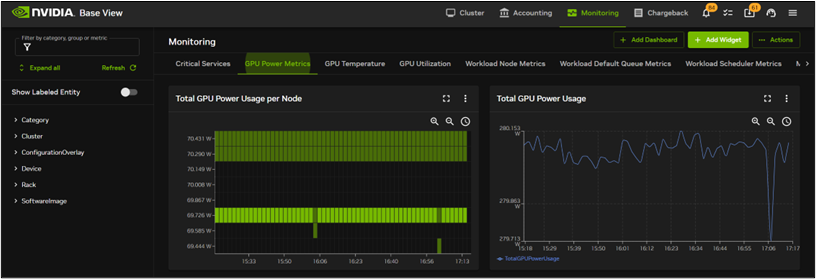
workerノードのGPU Powerステータス確認例
ここで重要なのは、GPUクラスタ運用は「ツールを揃える」だけでは不十分で、運用の一貫性(同じ手順・同じ基準・同じ状態を維持すること)が必要な点です。
というのも、GPUサーバが複数台になると、OS/ドライバ/OFED/CUDAなどの組み合わせ差分や、ノードごとの設定変更による構成ドリフトが発生しやすくなり、「一部のノードだけ挙動が違う」「同じジョブなのに結果や性能が安定しない」「障害の再現ができず切り分けに時間がかかる」といった問題につながります。
さらに、更新手順や適用範囲が担当者ごとに異なる場合、更新漏れやセキュリティ対応の抜けが起きやすく、監査対応や説明責任の観点でもリスクになります。
したがって、クラスタ全体で「同じ役割のノードは同じ状態」「変更は同じ手順で適用」「異常時は同じ導線で検知・復旧」という一貫した運用を実現することが、安定稼働の前提になります。
そこで登場するのが、クラスタ運用に必要な要素を統合し、運用手順の標準化を容易にするクラスタ管理ソフトウェアであるNVIDIA Base Command Managerです。
1.3 BCMが担う基盤運用タスク
BCMが担う基盤タスクとして、計算ノードのプロビジョニング、ソフトウェアイメージの設定、ロール割り当て、一般的なクラスタ管理が挙げられています。このあたりは、運用標準化の中核です。
具体的には次の通りです。
- 計算ノードのプロビジョニング(OS展開や初期設定の標準化)
- ソフトウェアイメージの設定(役割ごとのイメージ管理)
- ロール(役割)、ユーザー権限の割り当て
- 一般的なクラスタ管理(増設・更新・保守の運用統一)
運用インターフェース(GUIとCLI)
可視化が必要な理由
クラスタ規模が大きくなるほど、障害や性能劣化の兆候は複数のレイヤーに分散して現れます。
- GPU/NIC/ストレージ/ジョブスケジューラ など...
そのため、「どこで何が起きているか」を把握できていないと初動が遅れます。
これを防ぐのが可視化の役割です。
自動化が必要な理由
一方で、原因が分かっても、対処や日常作業を人手で都度行う運用では次の課題が生まれます。
- 手順の揺らぎによる設定差分(構成ドリフト)
- 更新漏れ
- 作業時間・品質の担当者依存
そこで、自動化により、プロビジョニング・設定適用・再起動・更新・復旧といった作業を同じ手順で繰り返し実行できるようにし、作業の再現性と速度を担保します。
このためBCMは、状況把握を行うBase View(GUI)と、手順のスクリプト化・自動実行に向くcmsh(CLI)の双方を提供します。
以下は実際のBCMの管理画面の例となります。
- Base View(GUI):日々の運用(利用状況・健全性確認、各種操作)をGUIで行えるインターフェースとして提供されます。
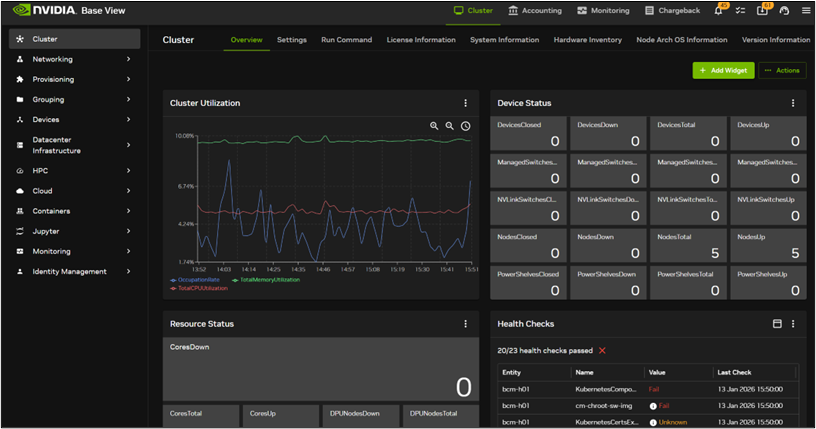
クラスタ全体のステータス表示例
- cmsh(CLI):運用手順をスクリプト化・自動化する際に役立ちます。
CLIを用いてノードのHostnameとIPアドレスを一括で確認し、2ノードを再起動している例です。


1.4 現場で差がつく強み
ここからは、機能カタログではなく「現場で事故を減らす」という観点でポイントを整理します。
BCMが現場で活用できるのは、事故の原因になりがちな運用の揺らぎを仕組みで抑えられる点にあります。
具体的には次の通りです。
- ノードをカテゴリで束ね、同じ役割のノードを同じ状態に保つ(構成ドリフトの抑制)
- 変更作業を安全な手順に寄せ、判断ミスによる停止を減らす
- 監視と復旧の導線を揃え、初動から復旧までの標準手順を作る
GPUクラスタでは資源の見え方のズレ(MIG/ドライバ/スケジューラ)が混在し、事故につながりやすい傾向があります。前提を揃えることで切り分けが容易になり、不可解な障害も減らせます。
加えて、更新の抜け漏れを抑えられるため、監査やCVE対応の説明責任も果たしやすくなります。
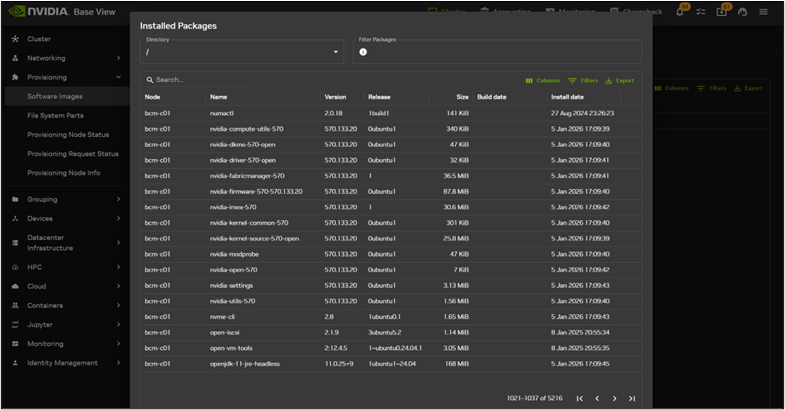
展開イメージのパッケージ表示例
1.5 セキュリティと更新
BCMは、OS/ドライバ/関連スタックの更新をクラスタ全体で揃える運用に寄せやすく、更新漏れや構成差分を減らします。
また、セキュリティ情報やリリースノートに沿って更新計画を立てやすく、CVE対応や監査対応の説明もしやすくなります。
参考:NVIDIA Security(セキュリティ情報)
https://www.nvidia.com/en-us/security/
1.6 まとめ
BCMは、GPUクラスタ運用で事故が起きやすい「ノード展開(プロビジョニング)」「イメージ管理」「ロール/カテゴリによる構成管理」「監視」「運用インターフェース(GUI/CLI)」を統合し、運用手順の標準化を現実的にするクラスタ管理ソフトウェアです。
ノードごとの手作業に頼る運用では、台数が増えるほど設定差分(構成ドリフト)や更新漏れが生まれ、原因切り分けにも時間がかかります。BCMを軸にすると同じ役割のノードを同じ状態に保ちやすくなり、「一部のノードだけ違う」ことに起因するトラブルを減らせます。
さらに、監視と運用操作が同じ導線にあることで、異常の検知から一次切り分け、復旧までを一定の手順で回しやすくなります。結果として、日々の変更・拡張・障害対応を属人化させずに回すための"運用品質の土台"としてBCMが活用できます。
次回は、BCM Head Nodeの展開とGPUクラスタ構築を、実際の画面を用いて解説していきます。
他のおすすめ記事はこちら
著者紹介
SB C&S株式会社
ICT事業本部 技術本部 第1技術統括部
第2技術部 1課
間山 翔宇
VMware vExpert




