


みなさん、こんにちは。SB C&Sの金井です。
今回は、アメリカ・ラスベガスにて開催された HPE 最大規模の年次イベント「HPE Discover Las Vegas 2026」に参加してきました。
本記事では、現地の様子やイベント内で発表された情報をご紹介します。
本イベントでは、主に VMEや Morpheus に関する情報収集を行っていたため、本記事の内容はHPE製品の中でも Hybrid Cloud 領域に寄った内容となっております。あらかじめご了承ください。
1. はじめに
Discover は、HPE が毎年開催している最大級のグローバルカンファレンスイベントです。
今年は、アメリカ・ラスベガスで6月16日から19日までの4日間にわたって開催され、1万人規模の参加者が集まりました。
初日の基調講演を皮切りに、参加者は各分野のセッションや展示ブースを巡りながら、HPE の最新技術や今後の戦略についてキャッチアップを行います。
私自身、先月タイ・バンコクで開催された技術者向けイベント「Tech Jam」にも参加しましたが、Discover はその規模が圧倒的でした。展示ブースの数や広さはもちろん、発表内容も HPE 全社の戦略や最新製品を網羅しており、まさに HPE の現在地と未来を体感できるイベントでした。
Tech Jam の様子はこちら をご覧ください。

2. AI 時代の中心はネットワーク(基調講演)
基調講演では、HPE CEO アントニオ・ネリ氏が登壇し、AI 時代に企業がどう変わるべきか、そして HPE がどんな未来を描いているのかを語りました。
内容は非常に広範囲でしたが、全体を通して一貫していたテーマは 「AI × ネットワーク × 自律化」でした。
ここからは、基調講演のポイントを私なりに整理してご紹介します。

基調講演の中で何度も登場したのが、「START WITH THE NETWORK」というメッセージです。
AI というと GPU に注目が集まりがちですが、HPE は「AIを支えるのはネットワークである」と強調していました。
大規模な AI クラスターでは膨大なデータがサーバー間を行き来するため、GPU 性能だけでなく、ネットワーク性能が AI 全体の処理能力を左右します。
その象徴的な発表として、HPE は AI 向けサーバー、ストレージ、管理基盤を組み合わせた「HPE AIデータセンターソリューション」に、HPE Juniper Networking を統合することを発表しました。これにより、AI 時代に求められるコンピュートからネットワークまでを含めた包括的なインフラを提供する体制を強く打ち出していました。

続いて、印象的だったのがエージェント型 AI です。
AI 時代は、Copilot を始めとする生成 AI を利用する段階から、AI エージェントが自律的に業務を遂行する「Agentic Enterprise」へ移行しつつあります。
つまり、AI が人の代わりに IT 運用を監視・判断し、修復する世界が現実に近づいているということを表現しています。

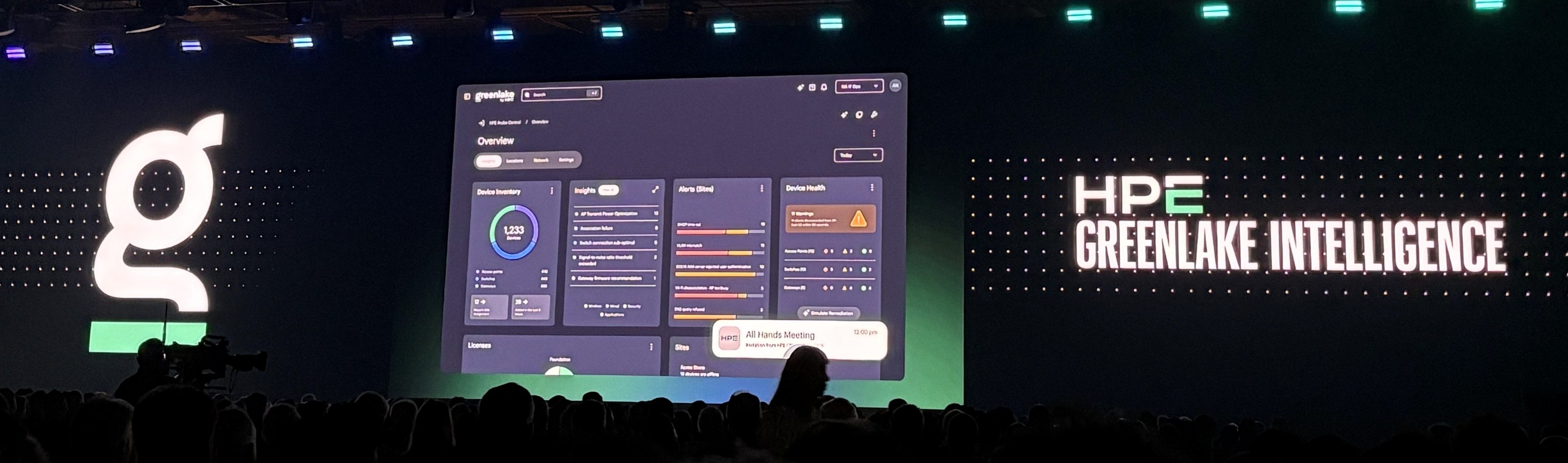
その Agentic Enterprise を支える中核技術として紹介されたのが「GreenLake Intelligence」です。
GreenLake Intelligenceは、HPE GreenLake Platform 上で動作する複数の専門AIエージェントを連携させ、環境全体の問題解決や運用の最適化を自律的に実現する知能レイヤーとして位置付けられています。
GreenLake Platformには、サーバー管理の Compute Ops Management や、ストレージ管理の Data Services Cloud Console など、各領域に特化した管理ツールが用意されています。これらのツールは従来通り個別の UI を持ちますが、 GreenLake Intelligence はそれらを置き換えるものではありません。代わりに、各ツールの AI エージェントを横断的に連携させ、システム全体の状況を把握しながら、複数の視点から問題を分析して最適な解決策へ導く役割を担います。
さらに、ユーザーは Copilot を通じてサーバー、ストレージ、ネットワークなどを横断的に操作できるため、複数の管理画面を行き来することなく、1つの画面から環境全体を分析し、必要に応じて自動修復まで実行可能です。
要するに、サーバー・ストレージ・ネットワークなどの管理ツールを個別に操作するのではなく、Copilot からまとめて状況を確認し、AI の支援を受けながら環境全体の運用やトラブル対応を行えるようになることが GreenLake Intelligence の目指す世界です。
そして、AI による運用自動化を実現するソフトウェア群として Cloud Ops Software の紹介がありました。
Cloud Ops Software は、「Observability(可観測性)」と「Automation(自動化)」を統合した運用基盤で、複雑化したマルチクラウド環境を一元的に管理するためのソフトウェア群です。
Morpheus(プロビジョニング・自動化)、OpsRamp(AIOps・監視・インシデント対応)、Zerto(データ保護・レジリエンス)という3つの製品を統合し、クラウド・オンプレミス・エッジを横断した運用の最適化を実現します。
HPEは、これらの製品を単体で提供するのではなく、Cloud Ops Softwareとして統合することで、AIを活用した自律型運用の実現を目指しています。
Cloud Ops Softwareについては、こちらをご覧ください。

一方で、HPE の AI 戦略はソフトウェアだけではなく、それを支えるインフラにも及びます。AI を実際に動かすためのインフラについても、多くの発表がありました。
AI 活用が進む中で、データセンターは従来の「計算する場所」から、インテリジェンスを生産する「AI ファクトリー」へと進化しています。HPE は今回の Discover で、この AI ファクトリーを構成するGovernance(統制)・Data(データ)・Scale(拡張性) の 3 要素を軸に、次世代 AI インフラの方向性を示しました。

その中でも、AI ファクトリーの計算基盤を担うサーバーとして、新たに HPE ProLiant Compute DL394 Gen12 が発表されました。NVIDIA Vera CPU を採用し、1.2TB/s のメモリ帯域 とNUMA を排除したモノリシック設計 により、AI推論やデータ処理、エージェント型AIの実行に最適化された、AI 時代を見据えた CPU サーバーです。さらに GPU を最大 2基まで搭載可能で、AI ファクトリーの汎用計算ノードとして柔軟に活用できます。

今回の基調講演を通じて感じたのは、HPE が単なるサーバーベンダーやインフラベンダーから、AI 時代のプラットフォームベンダーへと大きく舵を切っていることです。
ネットワーク、AI ファクトリー、GreenLake Intelligence、そしてCloud Ops Softwareなど、それぞれの発表は個別の製品紹介ではなく、「AI を安全かつ効率的に運用するための統合プラットフォーム」を実現するためのピースとして位置付けられていると感じました。
3. VME セッション
ここからは VME ・Morpheus のセッションで得た新情報についてご紹介します。
3.1. 第3の製品「Advanced」について
VME 製品ポートフォリオに新しく「Advanced」の追加が発表されました。
Advanced は Standalone と Enterprise の中間に位置するエディションで、プライベートクラウド構築に必要な機能が追加されています。
それぞれの位置づけとしては、以下となります。
※本画像では「VM Essentials」という名称が使用されていますが、本ブログでは従来の呼称に合わせて「Standalone」と表記します。
- Standalone:仮想化基盤向け(VVS 相当 )
- Advanced:プライベートクラウド向け(VVF 相当)
- Enterprise:マルチクラウド・サービスプロバイダー向け(VCF 相当)
※比較する上で終息済みの vSphere ライセンスも記載しています。
VVS は終息済みの製品です。
Advanced では、以下の機能が利用可能になります。
- HVM(KVMハイパーバイザー)の管理
- HKS(HPE Kubernetes Service)の管理
- SDN 機能
- サービスカタログ機能
- ワークフロー自動化

Advancedでは、従来のHVMによる仮想化基盤に加え、Kubernetes やネットワークまで含めて統合管理できるプライベートクラウド基盤として利用できるようになります。
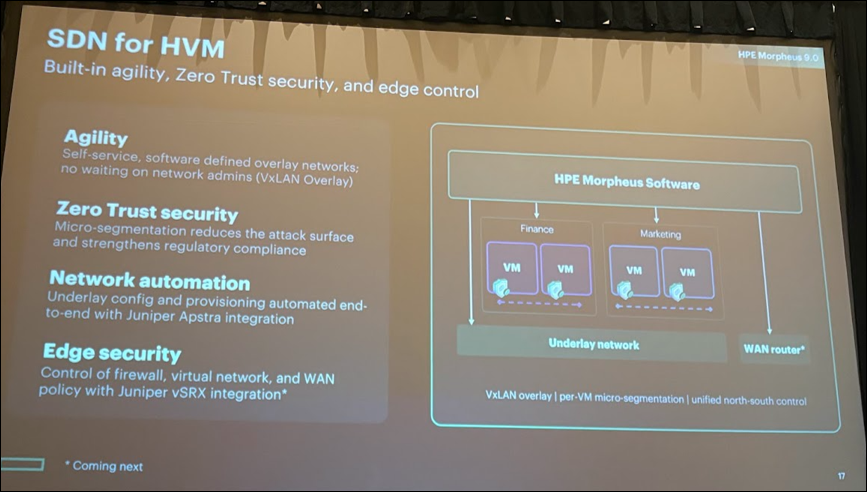
注目機能の一つが、Advanced から利用可能となる SDN(Software Defined Networking)です。
SDN は HPE が買収した Juniper Networks の技術をベースとしており、ネットワークの仮想化や自動化を実現します。
これにより、仮想マシン展開時のネットワーク設定やポリシー適用を自動化できるほか、ゼロトラストセキュリティに対応したネットワーク構成も実現可能になります。
3.2 Morpheus 9.0 最新情報について
6月中旬に Morpheus 9.0 のバージョンがリリースされました。
Standalone および Enterprise の大きなアップデートをいくつかご紹介します。

アップデートされた機能は以下となります。
この中から会場で紹介された主要機能をいくつかご紹介します。
◇Standalone のアップデート
- Bulk Migration の強化
- メモリオーバーコミットの実装
- ストレッチクラスターのサポート
- Pacemaker の廃止(代わりにMorpheus エージェントを使用)
- 2ノードGFS2 クラスターのサポート
- vGPU の追加(今後のアップデートで追加予定)
◇Enterprise のアップデート
- Orchestration Copilot の実装
- SDN の実装(秋実装予定)

まずは、Bulk Migration の機能強化についてです。
Bulk Migration は HVM version 8.0.8 から追加された、VMware 環境の仮想マシンを最大20台まで移行できる機能です。
移行手順などは、こちらをご覧ください。
新しいアップデートとしては、2点になります。
1つ目は、VirtIO ドライバーの自動インストールです。
従来はWindows 仮想マシンを移行する際に、VirtIO ドライバーを手動で1台ずつインストールすることが必要でしたが、今回のアップデートで自動インストールされるようになりました。これにより、移行前の事前準備作業を大幅に削減できます。
2つ目は、NFS データストアのサポートです。
従来、移行先の HVM データストアはGFS2 データストアのみ選択可能でしたが、今回から NFS データストアも移行先として選択できるようになりました。既存の NFS ストレージ環境を活用しながら移行できるため、柔軟な移行計画を立てやすくなっています。
HVM の移行方式としては、Zerto を利用した移行も選択できますが、今回の Bulk Migration の強化により、用途に応じて移行方式を選択できるようになりました。
Bulk Migration は、標準搭載される移行機能であり、比較的小規模な環境や計画停止を伴う移行に適しています。移行前の検証機能や一括移行機能も備えており、VMware から HVM への移行作業を効率化できます。
一方で、Zerto は継続的なレプリケーションを利用した移行を実現します。移行期間中もデータを継続的に同期し、切り替え時の停止時間を最小限に抑えることができるため、本番システムや停止時間を極力短くしたいワークロードに適しています。また、移行後も DR(災害対策)やサイバーリカバリー用途として活用できる点が特徴です。

続いて、ストレッチクラスターについてです。
ストレッチクラスターは、複数拠点にまたがる HVM 環境を単一クラスターとして構成し、高可用性を実現する機能です。
2つのサイト間でストレージを同期レプリケーションし、片方のサイトがダウンした場合でも、もう一方のサイトでサービスを継続することができます。
本機能は HPE Alletra MP の同期レプリケーション機能(Peer Persistence)を利用するため、ストレージとして Alletra MP が必要となります。

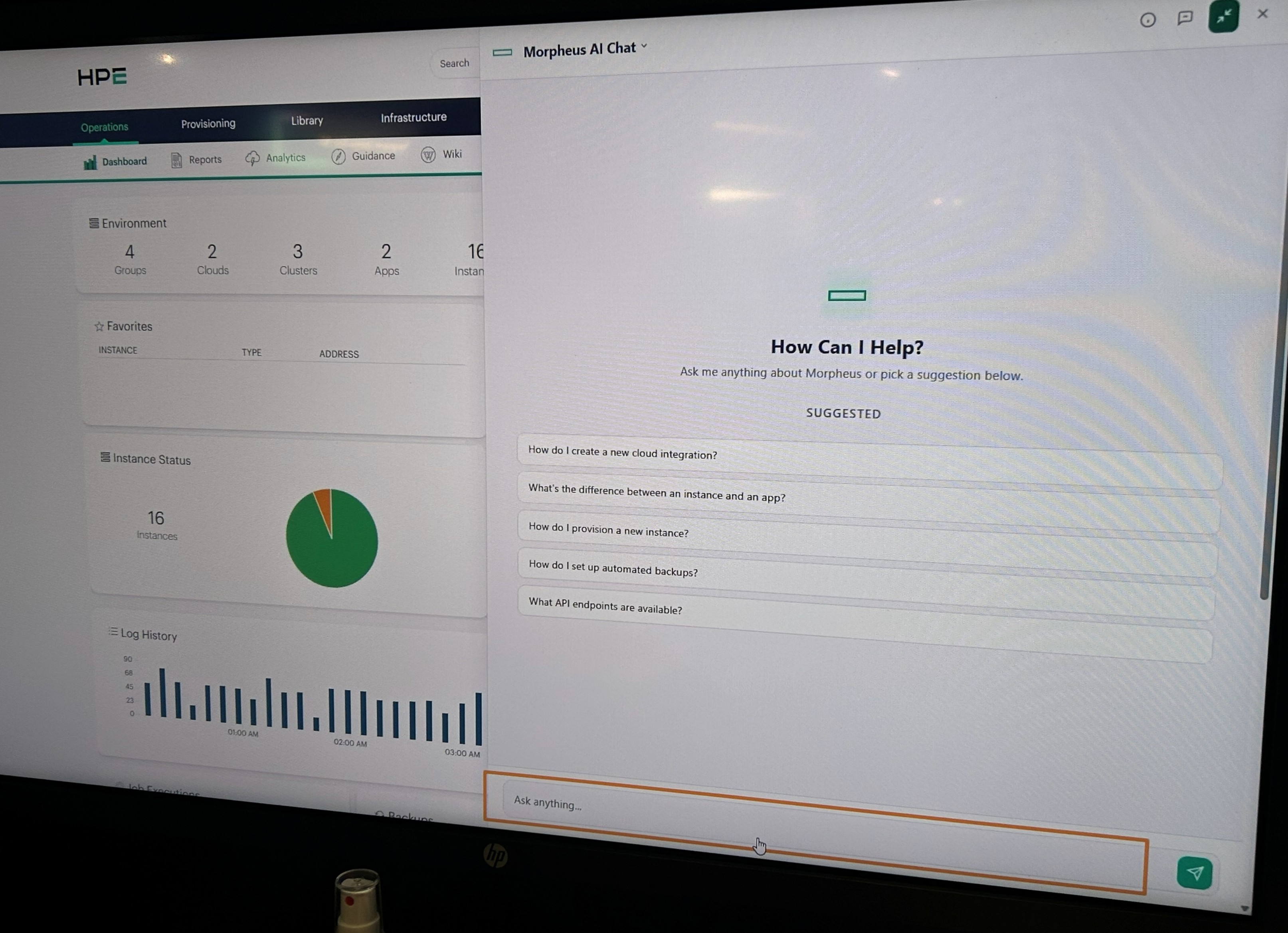
最後に Enterprise 機能の Orchestration Copilot についてです。
Orchestration Copilot は、Morpheus 環境の情報をもとに対話形式で運用を支援する AI アシスタントです。
チャット形式で、コスト分析や利用状況の確認やソースのプロビジョニング、ポリシー作成などを指示することができます。また、MCP(Model Context Protocol)に対応しており、OpenAI や GitHub Copilot などの外部 LLM との連携も可能です。

展示会場では、Morpheus の画面からチャット形式で指示するデモの様子を確認できました。
3.3 Morpheus Central について
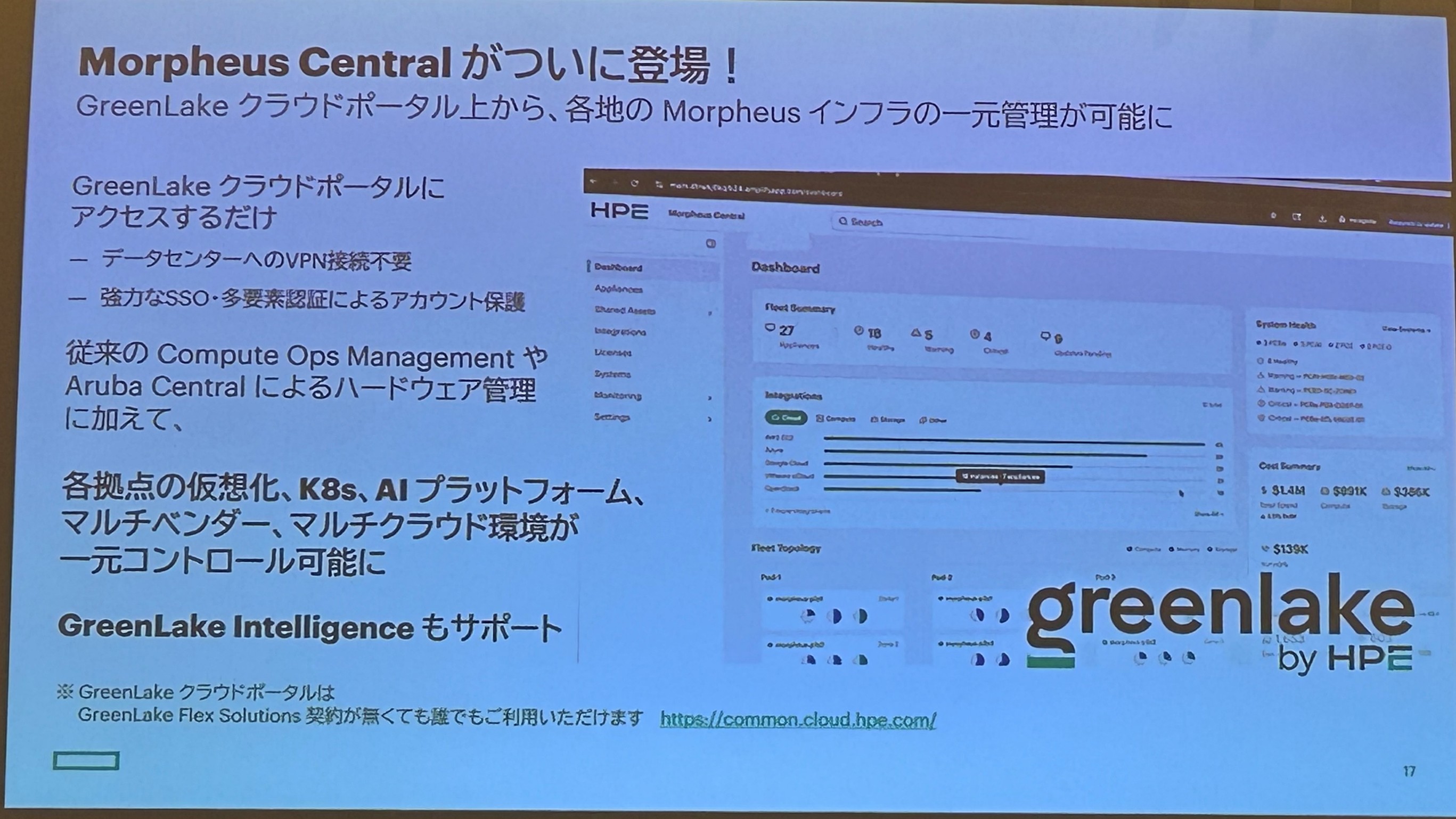
今回の発表では、新たに Morpheus Central が紹介されました。
Morpheus Central は、GreenLake Platform から各拠点ごとに管理していた Morpheus 環境を一元管理するためのサービスです。また、GreenLake Intelligenceとも連携し、各拠点のリソース利用状況や運用状況を可視化できるようになります。
複数のデータセンターやクラウド環境で Morpheus を運用している企業にとって、運用管理の効率化につながる機能として期待されます。
HPE は Morpheus を単なる仮想化管理ツールではなく、複数拠点・マルチクラウド環境を統合管理するプラットフォームとして進化させようとしていることが感じられました。
3.4 VME 移行支援キャンペーン
今回のセッションでは、VMware から VME への移行を支援する2つのキャンペーンも紹介されました。
1つ目は、移行期間中のライセンスコストを抑えるためのキャンペーンです。
VMware 環境から VME へ移行する場合、一時的に両方の環境を並行運用する必要があります。そのため、移行期間中は二重のライセンスコストが発生してしまいます。
この課題に対し、HPE では一定の条件のもとで VME のライセンスを1年間無償提供 するキャンペーンを実施予定です。
2つ目は、仮想マシンの移行をサポートするキャンペーンです。
HPE Zerto を利用した移行支援として、Zerto ARE 25ライセンスを1年間1ドルで提供するキャンペーンが紹介されました。Zerto を利用することで、継続的なレプリケーションによる低ダウンタイム移行が可能となり、本番環境の移行リスクを低減できます。
なお、これらのキャンペーンについては、現時点では国内提供可否や条件について検討中とのことで、内容が変更される可能性があります。

ここまで VME および Morpheus に関する最新情報をご紹介してきました。
現在は VMware からの移行が大きなテーマとなっていますが、今回の発表からは、HPE が単なる移行先のハイパーバイザーを提供するのではなく、仮想化、Kubernetes、SDN、AI運用を統合したプラットフォームの実現を目指していることが伝わってきました。
VMware からの移行を検討する企業にとっては、「移行ツールがある」だけではなく、「移行後の運用まで見据えたプラットフォームになってきている」という点が、今回のアップデートの大きなポイントだと感じました。
4. まとめ
最後に、今回初めて Discover に参加しましたが、HPE 最大級のイベントというだけあり、その規模や展示内容、発表の数々に大きな迫力とワクワクを感じました。
普段は製品や資料を通して触れている技術も、実際に開発者や製品担当者の話を聞くことで理解が深まり、HPE が目指す方向性をより具体的に感じることができました。
今後も進化を続ける HPE の技術動向を追いかけながら、機会があればぜひ次回の Discover にも参加したいと思います。
VME に関するお知らせ
著者紹介

SB C&S株式会社
ICT事業本部 技術本部 第1技術統括部 第1技術部 2課
金井 大河 - Taiga Kanai -




